Utilisation avancée des métadonnées
Mis à part les tags, les dictionnaires (paires clés/valeurs) et les pièces jointes, OMERO ne propose de base pas de solution très élaborée pour annoter les données, d’autant plus qu’il faut, dans les cas cités, les entrer manuellement (ce qui peut poser problème sur un nombre élevé d’images).
Heureusement, certaines applis OMERO permettent de régler (au moins partiellement) ces problèmes.
D’abord, les outils d’annotation et de saisie de métadonnées:
- OMERO.autotag (déjà abordé précédemment)
- OMERO metadata et les tableaux OMERO.table
- La collection de scripts serveur “Omero Bulk Annotation Tools”
- OMERO.forms
Puis les outils de recherche:
- OMERO.tagsearch (déjà abordé précédemment)
- OMERO.MAPR
- OMERO.parade
Utilisation de OMERO metadata et des tableaux OMERO.tables
OMERO metadata est un plugin utilisé pour manipuler en bloc les métadonnées sur OMERO, s’installant côté serveur.
Une documentation plus détaillée se trouve ici: https://github.com/ome/omero-metadata/#populate, et là https://omero-guides.readthedocs.io/en/latest/upload/docs/metadata-ui.html
Côté utilisateur, il s’utilise par le biais du script OMERO “Populate Metadata”, trouvable dans les scripts (icône d’engrenages), dans la section “import_scripts”. Ce script permet d’associer le contenu d’un fichier CSV en tant que métadonnées d’annotation d’un objet d’OMERO.
Une fois ouvert, la fenêtre suivante s’affiche:
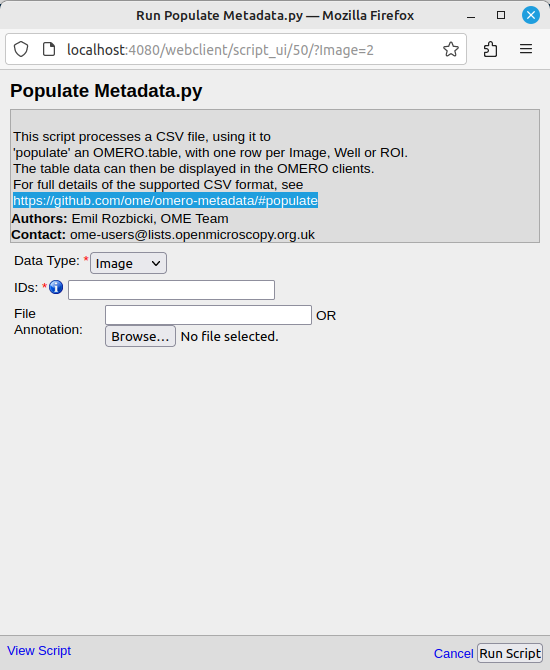
La liste déroulante “Data Type” permet de sélectionner le type de données auquel associer les métadonnées (“Plate”, “Screen”, “Dataset”, “Project”, “Image”). Le champ “IDs” correspond aux identifiants des items OMERO (“Plate”, “Screen”, “Dataset”, “Project”, “Image”) à annoter. Le champ “File Annotation”: permet d’entrer le numéro d’“Annotation ID” du fichier CSV ajouté en pièce jointe. Il est possible d’obtenir cette valeur en positionnant le pointeur de la souris dur le nom du fichier dans la liste de pièces jointes. Noter que cette façon de procéder NE PERMET PAS d’associer le contenu d’une pièce jointe d’un autre dataset.
Contenu du fichier CSV
OMERO.tables possède des types de colonne prédéfinis, avec des noms dédiés.
Pour un projet/dataset ou une image
Dans le cas d’un fichier associé à un “Projet”, le fichier devra comprendre au moins une de ces 3 colonnes (Note: respecter les espaces dans les noms de colonne):
Nom de colonne Type (informatique) de colonne Type de "header" détecté Notes
Dataset DatasetColumn dataset Permet l'entrée de l'ID du dataset.
Dataset Name StringColumn s(String) Permet l'entrée du nom du dataset.
Dataset ID DatasetColumn dataset Permet l'entrée de l'ID du dataset.
Dans le cas d’un fichier associé à un “Dataset” (et le cas échéant, un projet, si on souhaite au passage annoter les images), le fichier devra comprendre au moins une de ces colonnes:
Nom de colonne Type (informatique) de colonne Type de "header" détecté Notes
Image ImageColumn image Permet l'entrée de l'ID de l'image. Ajoute une nouvelle colonne 'Image Name' avec les noms des images.
Image Name StringColumn s Permet l'entrée du nom de l'image. Ajoute une nouvelle colonne 'Image' avec les identifiants des images.
Image ID ImageColumn image Permet l'entrée de l'ID de l'image. Ajoute une nouvelle colonne 'Image Name' avec les noms des images.
Dans le cas d’un fichier associé à une “Image” (et le cas échéant, un projet ou un dataset, si on souhaite au passage y annoter le contenu des images), le fichier devra comprendre au moins une de ces colonnes:
Nom de colonne Type (informatique) de colonne Type de "header" détecté Notes
ROI RoiColumn roi Permet l'entrée de l'ID de la ROI. Ajoute une nouvelle colonne 'ROI Name' avec les noms des ROIs.
ROI Name StringColumn s Permet l'entrée du nom de la ROI. Ajoute une nouvelle colonne 'ROI' avec les IDs des ROIs.
ROI ID RoiColumn roi Permet l'entrée de l'ID de la ROI. Ajoute une nouvelle colonne 'ROI Name' avec les noms des ROIs.
Les autres colonnes sont libres et correspondent aux autres données concernant les datasets ou images (dans les headers, séparer chaque mot par “_”, pas d’espace)
Ajouter des métadonnées sur un Projet, un Dataset ou une Image
Cliquer sur “Run Script” pour lancer le script. Après succès de l’opération, le tableau de données apparaîtra dans les métadonnées du dataset, dans la liste déroulante “Attachments” sous la dénomination “bulk_annotations”:
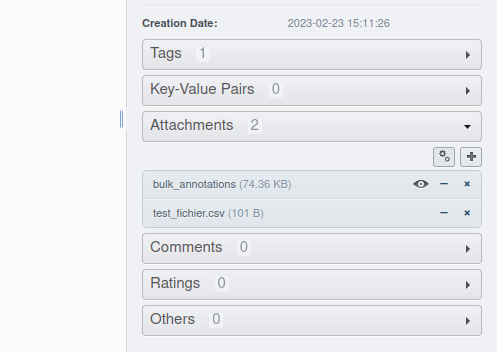
Noter la présence d’un oeil à côté de l’entrée du tableau. Celui-ci permet de visualiser le contenu du tableau dans un autre onglet:

Cet onglet vous permettra de télécharger votre tableau au format CSV (en cliquant sur Show current page as: CSV) ou au format JSON (en cliquant sur Show current page as: JSON). Le bouton “Whole Table” ne sert à rien (il est buggé et ne fait que télécharger en boucle l’entête du fichier à chaque requête GET)
Le tableau vous permet également de retourner vers OMERO à l’image correspondante, en cliquant sur l’identifiant de l’image (dans la colonne “Image”)
Sur l’interface principale d’OMERO, vous pourrez remarquer que les annotations sont propagées à chaque image: chaque image OMERO dispose d’une liste déroulante “Tables”:
Utilisation des scripts de la collection “Omero Bulk Annotation Tools”
ATTENTION: ces scripts sont encore dans un état de finition laissant à désirer et sont donc très mal documentés.
Ils se trouvent à l’adresse suivante: https://github.com/mpievolbio-scicomp/obat
Un tutorial original (en anglais) se trouve à cette URL: https://github.com/mpievolbio-scicomp/obat/blob/master/readme.orig.md
Un tuto impliquant l’utilisation de ces scripts avec OMERO.forms (qui sera traité plus loin) se trouve ici: https://mpievolbio-scicomp.pages.gwdg.de/blog/post/2020-09-03_omerobulkannotation/
Ces scripts sont accessibles par l’icône des scripts (engrenage mécanique)
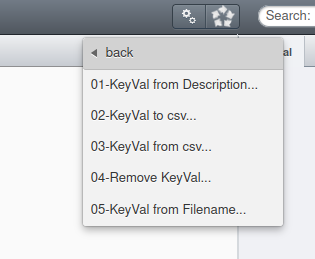
Cette collection comprend 5 scripts:
- 01-KeyVal from Description…
- 02-KeyVal to csv…
- 03-KeyVal from csv…
- 04-Remove KeyVal…
- 05-KeyVal from Filename…
Avant de chercher à utiliser ces scripts, il conviendra de savoir que les virgules sont utilisées comme séparateur. Par conséquent, elles ne devront PAS être utilisées dans les noms des fichiers (que ce doit sous OMERO ou hors OMERO) ou à l’intérieur des champs de valeurs du fichier. Ainsi, en cas de passage d’un fichier CSV en paramètre, elles ne devront PAS être utilisées en dehors de la séparation des champs de valeur.
“01-KeyVal from Description…”
Un tuto plus détaillé (en anglais) pour ce script est à cette adresse: https://code.research.uts.edu.au/MIF/OMERO-instructions/-/wikis/organising_data/Adding-Global-Key-Values
En sélectionnant ce script, la fenêtre suivante s’affiche:
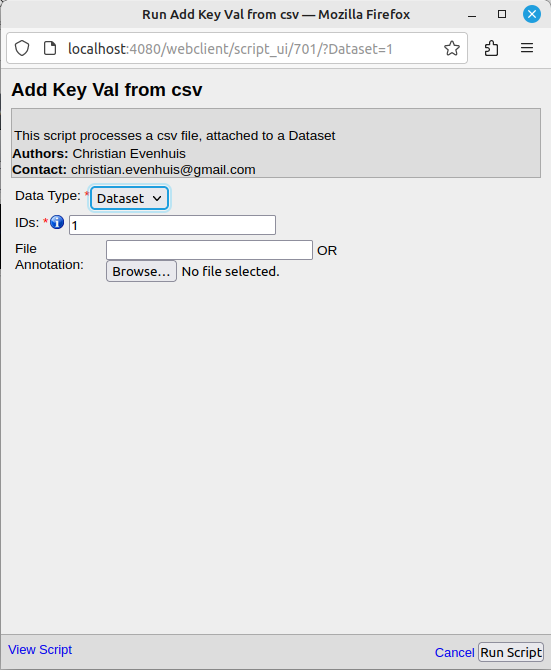
La liste déroulante “Data Type” permet de sélectionner le type de données concernées. Il n’y a en réalité pas de choix. Ce script ne s’applique qu’aux datasets OMERO.
Le champ “IDs” permet d’entrer les numéros des datasets sur lesquels appliquer l’opération.
Ce script s’applique a un dataset. Il permet d’ajouter des informations figurant dans la description en tant que paires clés/valeurs. Ces informations doivent être sous la forme suivante:
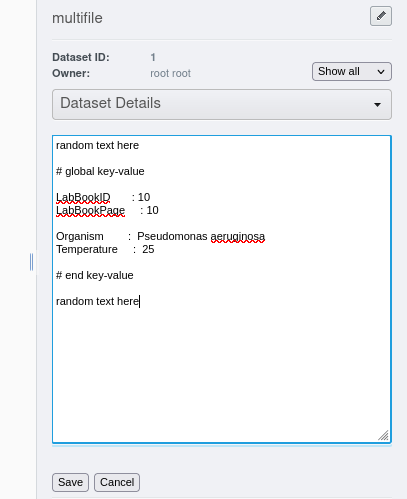
# global key-value
LabBookID : 10
LabBookPage : 10
Organism : Pseudomonas aeruginosa
Temperature : 25
# end key-value
Les informations à ajouter devront figurer entre les 2 balises “# global key-value” et “# end key-value”. Elles devront être sous la forme “clé:valeur” séparés par le caractère “:” (les espaces figurant dans l’exemple sont facultatifs).
Cliquer sur “Run Script” pour lancer le script.
“02-KeyVal to csv…”
Ce script s’applique à un dataset. Il permet de convertir les paires clés/valeurs (“Key-Value Pairs”) des images du dataset (pas du répertoire du dataset) en un fichier de texte brut au format CSV.
En sélectionnant ce script, la fenêtre suivante s’affiche:
La liste déroulante “Data Type” permet de sélectionner le type de données concernées. Il n’y a en réalité pas de choix. Ce script ne s’applique qu’aux datasets OMERO.
Le champ “IDs” permet d’entrer les numéros des datasets sur lesquels appliquer l’opération.
Cliquer sur “Run Script” pour lancer le script. Le fichier CSV apparaîtra en tant que pièce jointe (“Attachment”) au répertoire du dataset, sous le nom “multifile_metadata_out.csv”.
“03-KeyVal from csv…”
En sélectionnant ce script, la fenêtre suivante s’affiche:
Ce script s’applique à un dataset. Il permet d’associer les valeurs d’un fichier CSV attaché au dataset (dans la rubrique “Attachments”) aux images du dataset.
Le contenu du fichier CSV devra être sous la forme suivante:
filename, number_of_satanic_invocations
image_0.czi, 666
La colonne “filename” est obligatoire. La deuxième colonne n’est là que pour donner un exemple de valeurs, pour ceux qui n’auraient pas compris.
La liste déroulante “Data Type” permet de sélectionner le type de données concernées. Il n’y a en réalité pas de choix. Ce script ne s’applique qu’aux datasets OMERO.
Le champ “IDs” permet d’entrer les numéros des datasets sur lesquels appliquer l’opération.
Le champ “File Annotation”: permet d’entrer le numéro d’“Annotation ID” du fichier CSV ajouté en pièce jointe. Il est possible d’obtenir cette valeur en positionnant le pointeur de la souris dur le nom du fichier dans la liste de pièces jointes. Noter que cette façon de procéder NE PERMET PAS d’associer le contenu d’une pièce jointe d’un autre dataset.
Le bouton “Browse” sert théoriquement à sélectionner un fichier présent sur le disque dur de votre ordinateur. Ce bouton n’est pas fonctionnel (les scripts sont encore en état expérimental).
Cliquer sur “Run Script” pour lancer le script.
“04-Remove KeyVal…”
Ce script permet d’enlever tous les dictionnaires des images d’un dataset, et du dataset lui-même.
En sélectionnant le script, la fenêtre suivante s’affiche:
La liste déroulante “Data Type” permet de sélectionner le type de données concernées. Il est possible de choisir entre Dataset et Image.
Le champ “IDs” permet d’entrer les numéros des datasets sur lesquels appliquer l’opération.
Le champ “Descriptions” permet théoriquement d’entrer une nouvelle description pour chaque image du dataset (dans le cas d’un Dataset) ou pour l’image sélectionnée (sans le cas d’une Image), mais ne fonctionne pas.
Cliquer sur “Run Script” pour lancer le script.
“05-KeyVal from Filename…”
Un tuto en anglais pour ce script est à cette adresse (servant de base au tuto ci-dessous): https://code.research.uts.edu.au/MIF/OMERO-instructions/-/wikis/organising_data/filename/Extracting-Key-Values-from-filenames
En sélectionnant ce script, la fenêtre suivante s’affiche:
La liste déroulante “Data Type” permet de sélectionner le type de données concernées. Il n’y a en réalité pas de choix. Ce script ne s’applique qu’aux datasets OMERO.
Le champ “IDs” permet d’entrer les numéros des datasets sur lesquels appliquer l’opération.
Ce script effectue les opérations suivantes:
1: Récupère un schéma d’organisation des informations dans le nom du fichier (template) qui sera ajouté en description 2: Récupère les numéros associés à chaque information, qui seront ajoutés en description 3: Découpe les noms des fichiers selon le template de l’étape 1 pour en extraire les infos, et associe chaque info à la clé associée selon leur position dans le nom de fichier, puis stocke les paires clé/valeur en tant que métadonnées.
Voici un exemple de démonstration:
Exemple de titre: “150707_FishNewProbes_TRITC_Eurb388_01_snapshot_R3D.dv”
Dans cet exemple, le séparateur est clairement le caractère “_” (Underscore). Il est possible d’utiliser d’autres caractères.
Les informations nécessaires au parsing du nom de fichier seront ajoutées en description de cette façon:
# filename key-value
template *_*_*_*_*_snapshot_R3D.dv
1. DateOfExperiment
2. Probe used
3. FilterSet
4. GeneInsert
5. Replicate
# end key-value
Les informations à ajouter devront figurer entre les 2 balises “# filename key-value” et “# end key-value”. D’abord le template, puis les numéros/clés. Respecter la syntaxe du template (utiliser le caractère “*” pour représenter les informations entre chaque séparateur).
Le moyen le plus simple pour écrire le template est de copier un nom d’un des fichiers dans la boîte de description, puis de remplacer chaque partie importante du nom par un astérisque. En dessous écrire les numéros/clés (par exemple, “1.”, suivi du nom de la clé, puis incrémenter).
Cliquer sur “Run Script” pour lancer le script.
Utilisation d’OMERO.forms
La documentation officielle de cette appli se trouve ici: https://github.com/sorgerlab/OMERO.forms
OMERO.forms est une appli web a 2 facettes. La facette “administrateur” (ou à la limite, “chef d’équipe”) permet de:
- Concevoir un formulaire au format JSON
- Verrouiller l’attribution de ce formulaire à un projet OMERO, un dataset OMERO, ou à une image OMERO.
- Verrouiller la possibilité d’utilisation de ce formulaire à un ou plusieurs groupes.
La facette “utilisateur” permet de:
- Sélectionner un formulaire et l’associer à un projet, un dataset ou une image (selon les restrictions du formulaire).
- Remplir le formulaire.
- Le contenu du formulaire sera converti en paires clés/valeurs qui seront associées à l’objet.
1. Côté administrateur: OMERO.forms Designer
Pour accéder à OMERO.forms Designer, cliquer sur “Forms Designer” sur la barre d’outils OMERO. Un nouvel onglet s’ouvrira, et la fenêtre suivante s’y affiche:
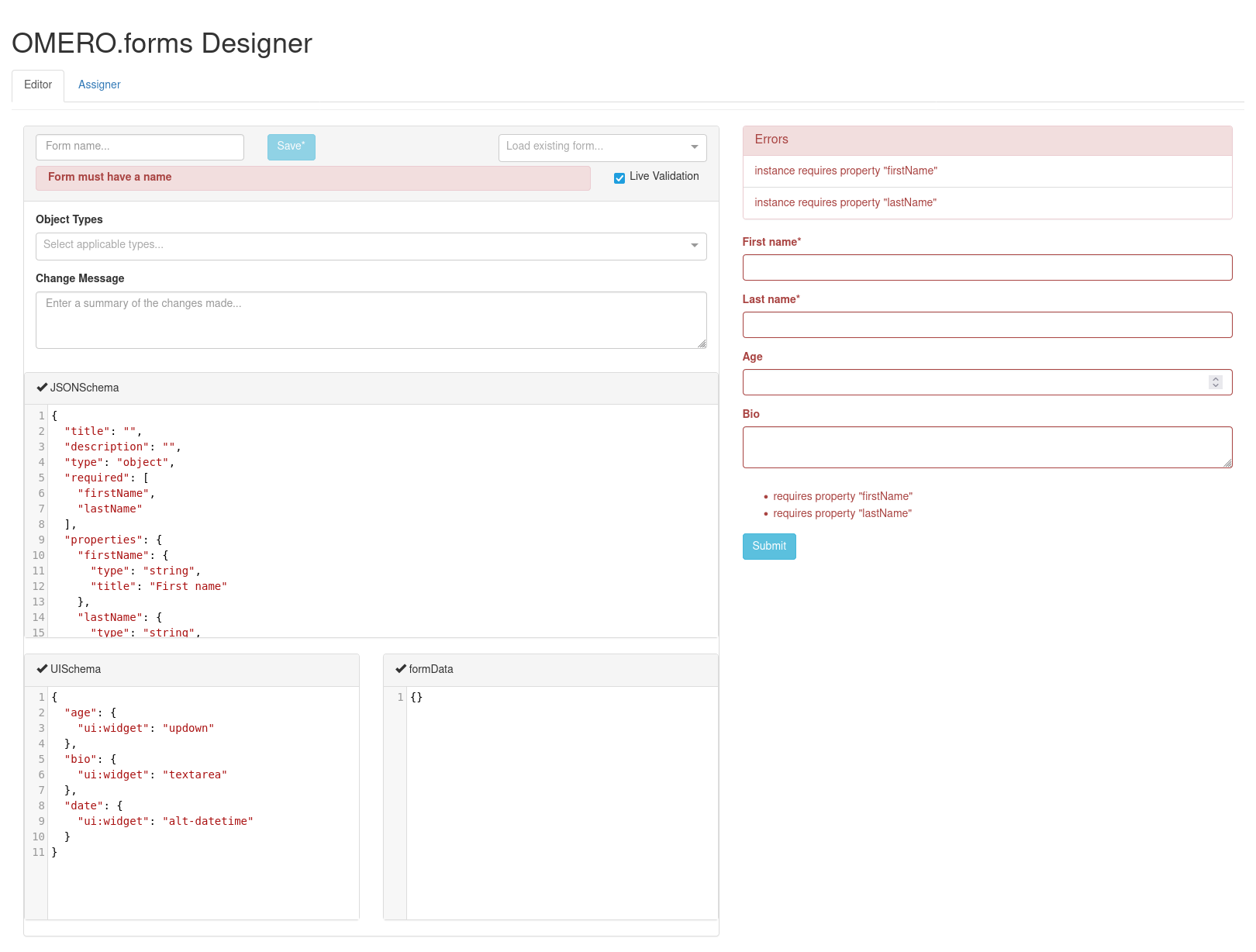
2 onglets sont accessibles: “Editor” et “Assigner”. L’onglet “Editor” est sélectionné par défaut.
Onglet “Editor”
L’onglet “Editor” permet de créer un formulaire. On peut y distinguer 2 régions.
La région de gauche est exclusivement dédiée aux modifications. Elle comporte plusieurs champs:
- Le champ “Form name” sert à donner un nom au formulaire. Il est obligatoire pour pouvoir le sauvegarder et le réutiliser.
- La liste déroulante “Load existing form” permet de charger un formulaire déjà enregistré pour pouvoir éventuellement y apporter des modifications (si c’es un formulaire que vous avez créé: il est impossible de modifier le formulaire de quelqu’un d’autre.) ou de créer un formulaire “dérivé” sous un autre nom.
- La case à cocher “Live Validation”
- Le champ “Object Types” permet de sélectionner à quel type d’entité ce formulaire sera attribué (“Project”, “Dataset”, “Screen”, “Plate”). Plusieurs choix sont possibles.
- Le champ “Change Message” permet d’ajouter un résumé des modifications apportées (ou d’écrire tout autre texte).
Sur la partie basse de la région de gauche se trouvent 3 champs de texte au format JSON, qui définiront le formulaire:
- JSONSchema, qui est le squelette du formulaire souhaité
- UISchema permet d’attribuer des propriétés d’interaction spécifiques à chaque champ du formulaire, selon les possibilités du type associé au champ du formulaire concerné
- formData contient les données entrées dans chaque champ du formulaire
La conception des formulaires utilise le langage déclaratif JSON Schema (http://json-schema.org/).
La documentation détaillée de l’utilisation du composant (mots-clés, syntaxe à utiliser…) permettant la conversion du texte JSON en formulaire au format HTML se trouve à cette adresse: https://rjsf-team.github.io/react-jsonschema-form/docs/.
Des exemples de formulaires, copiables/collables et modifiables au besoin du moment, se trouvent ici: https://rjsf-team.github.io/react-jsonschema-form/.
La région de droite est une maquette du formulaire telle qu’il sera aux yeux de l’utilisateur amené à le remplir. Cet aperçu comporte même un bouton “Submit”, cliquable, qui dans ce cas présent ne sert à rien.
Onglet “Assigner”
L’onglet “Assigner” permet de verrouiller/déverrouiller l’utilisation d’un formulaire pour tel ou tel groupe. On peut y distinguer 2 régions. En cliquant sur l’onglet “Assigner”, la page suivante s’affiche:
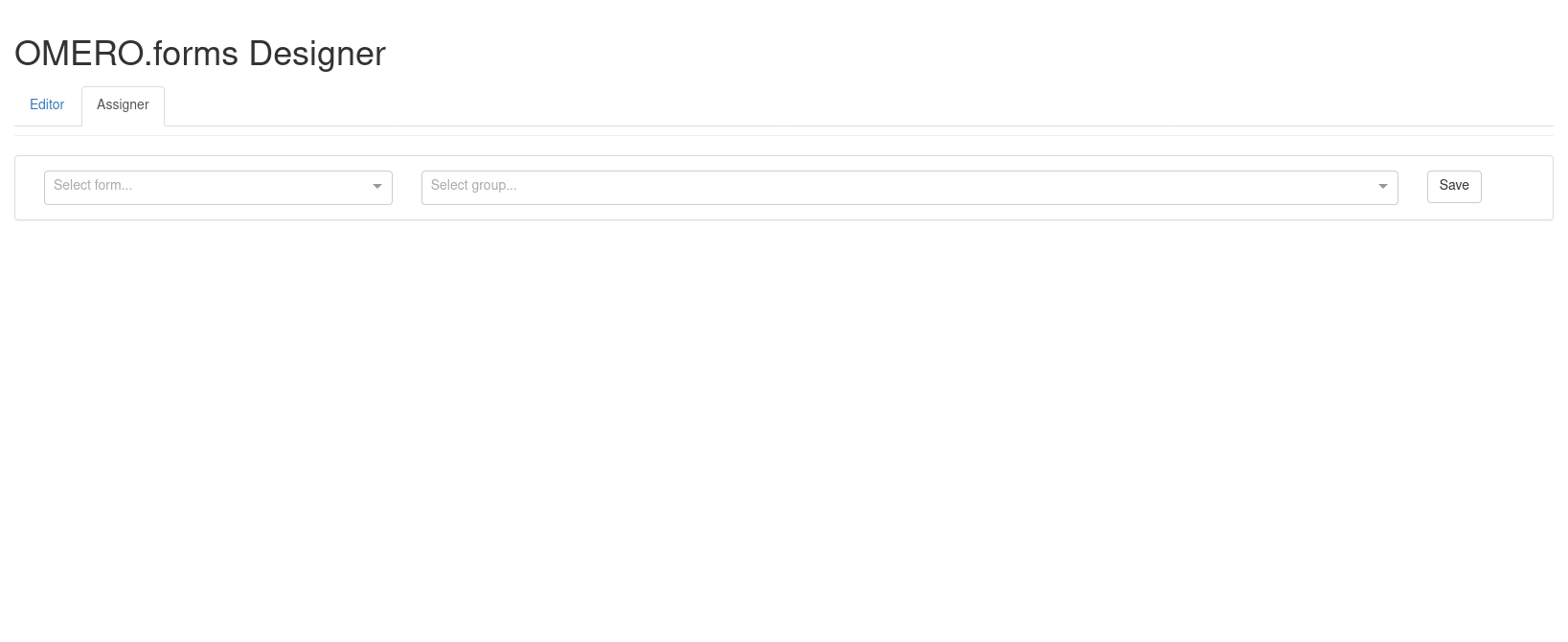
Contrairement à l’onglet “Editor” qui était particulièrement riche en contenu, l’onglet “Assigner” brille par sa sobriété. Il ne comporte que 4 composants:
- La liste déroulante “Select form…” permet de sélectionner un formulaire parmi ceux déjà créés.
- Le champ “Select group…” permet de sélectionner les groupes OMERO qui pourront utiliser le formulaire.
- Le bouton “Save” permet de sauvegarder les réglages de groupe pour ce formulaire.
- Le champ “Group Assignement” est un tableau permettant de visualiser quels groupes ont accès à quels formulaires.
Cela donne ceci:
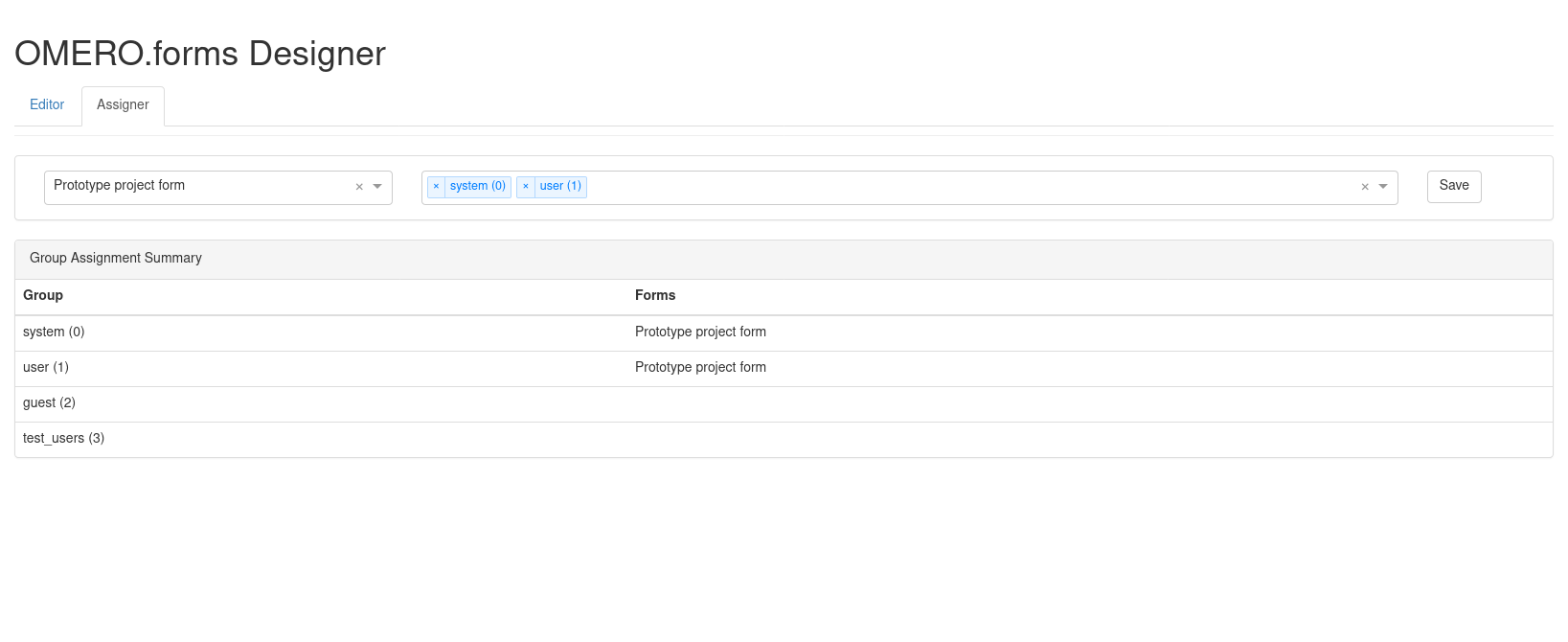
Cet outil est destiné à être utilisé par des administrateurs. Un simple utilisateur ne pourra modifier les attributions des formulaires aux groupes.
2. Côté utilisateur: OMERO.forms Designer
Pour utiliser un formulaire via OMERO.web, sélectionner d’abord un élément (projet, dataset), puis cliquer sur la petite liste déroulante permettant de changer de vue d’images (par défaut, elle est réglée sur “Thumbnails”).
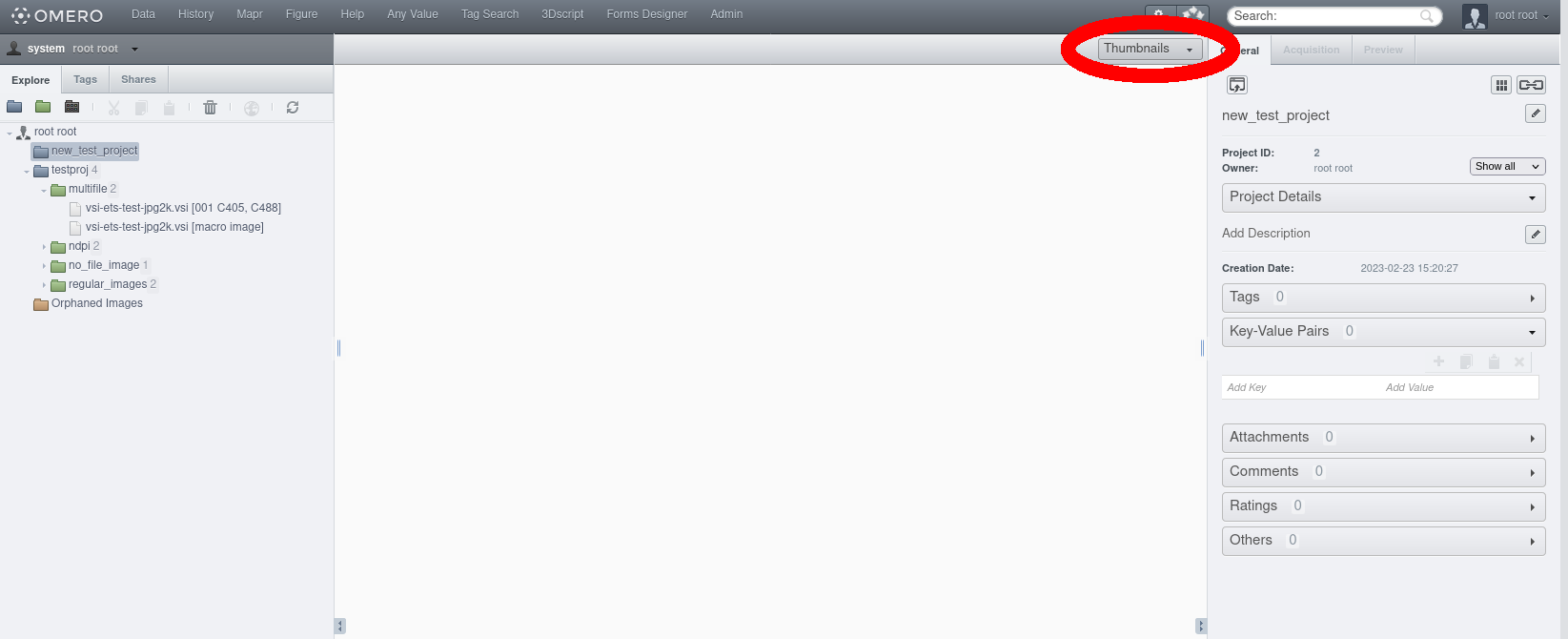
Sélectionner “Forms”. La vue suivante s’affiche:
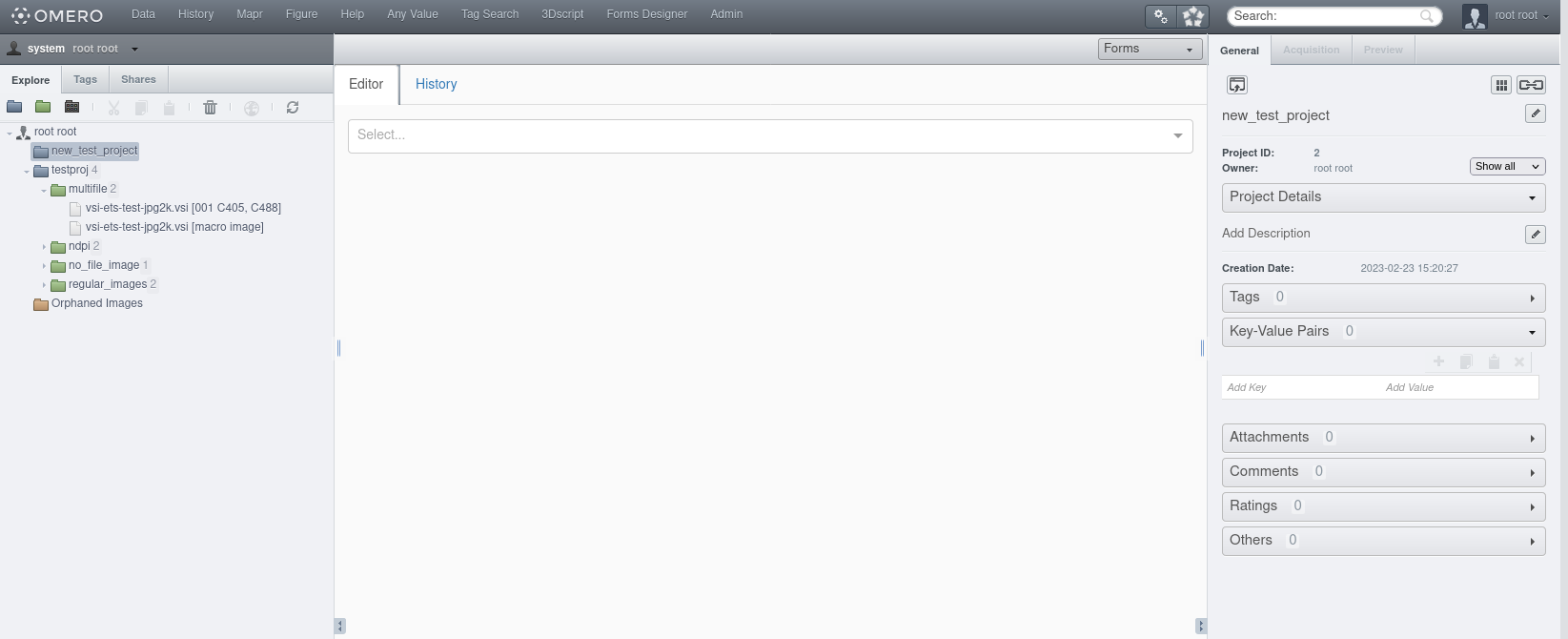
La vue propose 2 onglets: “Editor” (sur lequel vous êtes par défaut), et “History”, ainsi qu’une liste déroulante (“Select…”) permettant de sélectionner un formulaire. Sélectionner tout d’abord un formulaire. Celui-ci s’affiche:
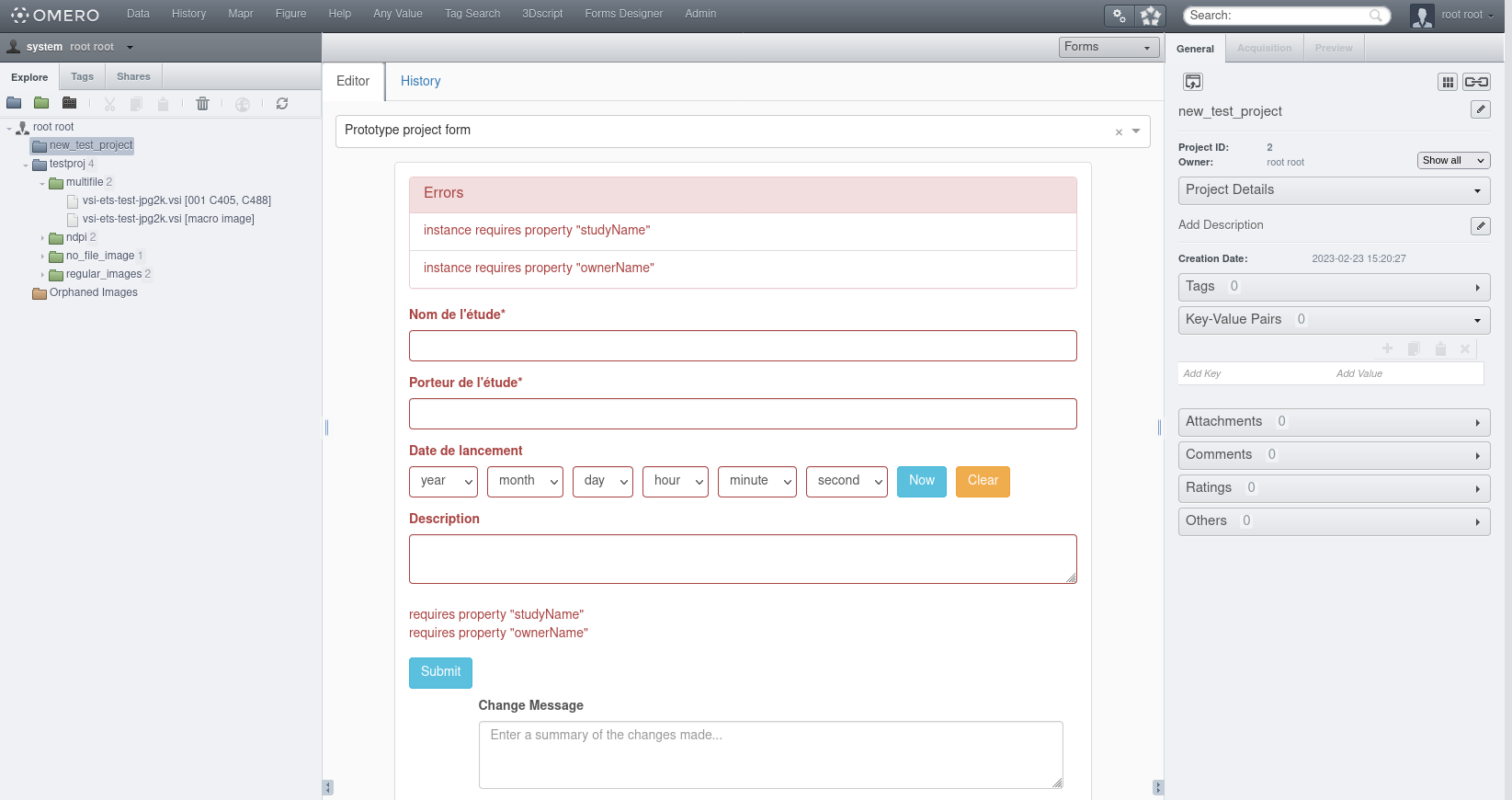
Remplir le formulaire, puis cliquer sur le bouton “Submit”. Le champ “Change Message” sert à saisir un message de commentaire en cas de changement ultérieur.
Après avoir cliqué sur “Submit”, les données entrées dans le formulaire seront associées à l’élément (projet, dataset…) en tant que paires clés-valeurs.
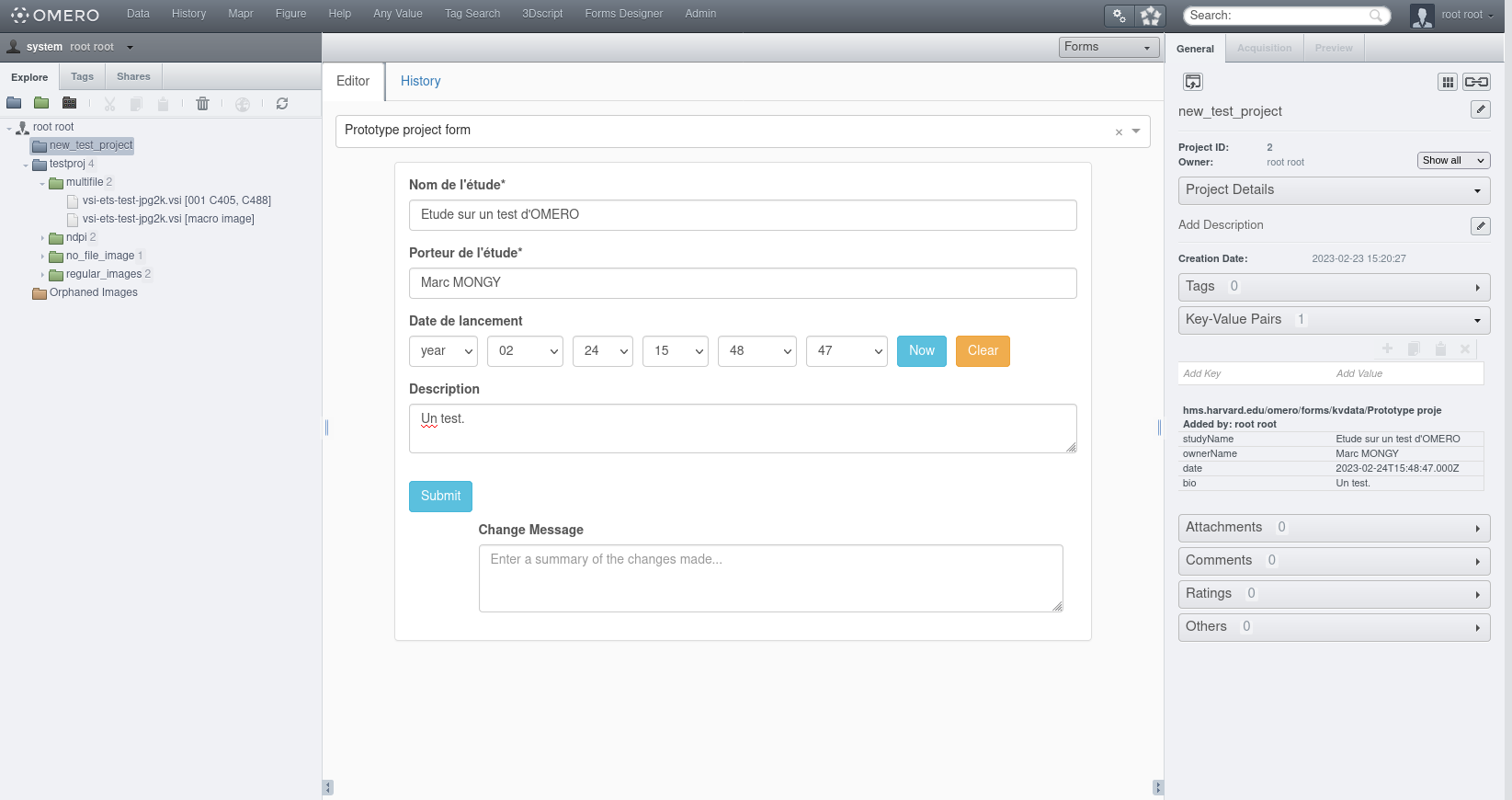
L’onglet “History” répertorie, le cas échéant, les changements ayant eu lieu, et conserve pour chaque entrée un visuel du formulaire (immuable: le bouton “Submit” est verrouillé) lors du changement.
Barre de recherche de base d’OMERO
OMERO dispose d’un utilitaire de recherche déjà très correct et polyvalent: la barre de recherche:

Celle-ci permet d’effectuer des recherches sur les noms (ou fragments de noms) de projets, datasets, images, tags, paires clés-valeurs, contenus de description…
Après une recherche (saisie de caractères dans la barre suivie d’un clic sur la loupe), réussie ou pas, la fenêtre suivante s’affiche:
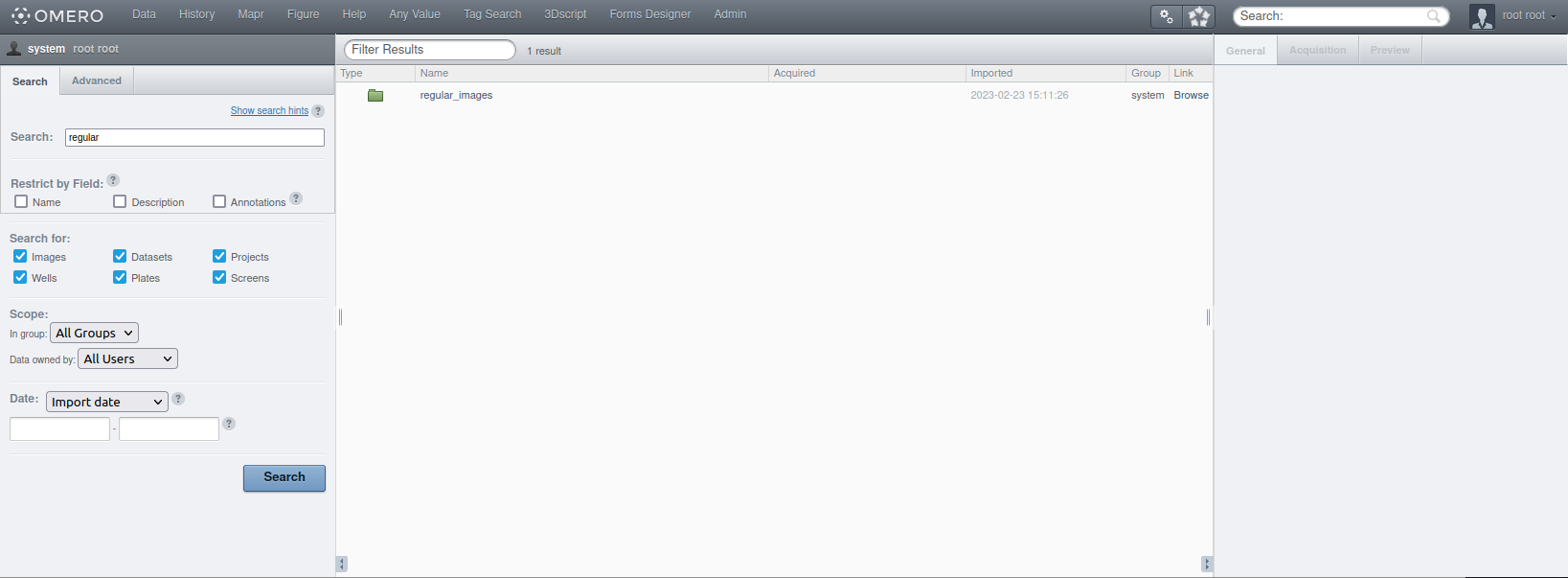
La région de gauche comprend 2 onglets: “Search” et “Advanced”.
L’onglet “Search” comprend plusieurs éléments:
-
Le champ “Search” permet de saisir ce que vous voulez. Il existe des astuces basées sur la syntaxe de Lucene (plus de détails et d’astuces de recherche ici: https://lucene.apache.org/core/2_9_4/queryparsersyntax.html) pour optimiser les résultats obtenus:
- Remplacer un caractère par “?” permet au moteur d’ignorer ce caractère et de faire des requêtes en utilisant toutes les caractères possibles pour cette position (“Single character wildcard”).
- Placer le caractère “*” (“Multiple character wildcard”) en début ou en fin de requète permet d’ignorer tous les caractères avant ou après la requète.
- Le mot-clé “AND” permet de faire une recherche sur plusieurs termes.
-
“Restrict by Field” permet de restreindre la recherche au nom de l’image, au contenu de la description, ou aux annotations (incluant les pièces jointes, les tags, les commentaires, les paires clés-valeurs…), selon la ou les cases cochées.
-
“Search for” permet de restreindre la recherche au type d’élément recherché (image, dataset, projet, voire puits, plaques, écran dans le cas d’images d’HCS).
-
“Scope” permet de restreindre la recherche de données sur un seul groupe et/ou un seul utilisateur de ce groupe. Sélectionner “All groups” et “All Users” pour lever toutes les restrictions.
-
“Date” permet d’effectuer une recherche par date. 2 types de date sont sélectionnables “Import date” (date d’importation de l’élément dans OMERO) et “Acquisition date” (date d’acquisition de l’image, enregistrée en dur dans le fichier image). Les 2 champs en-dessous permettent de sélectionner 2 dates entre lesquelles lancer la recherche.
L’onglet “Advanced” permet de lancer une recherche avancée.
Une documentation plus précise en anglais se trouve à cette adresse: https://omero-guides.readthedocs.io/en/latest/introduction/docs/search-omero.html
OMERO.parade
Le tuto à suivre est une reprise de https://wiki-biop.epfl.ch/en/Image_Storage/OMERO/OmeroParade
OMERO.parade est un plugin de metadata-mining pour OMERO.web. Il permet de filtrer des images selon plusieurs critères (tags, paires clés/valeurs, mais aussi nombre de ROIs, ou même selon des métadonnées issues de tableaux ou de fichiers CSV), et permet d’afficher des graphiques (“plots”) à partir des métadonnées. OMERO.parade gère également les tableaux OMERO.tables. Toutefois, quelque règles sont à assimiler (plus de détails ici: https://forum.image.sc/t/using-omero-parade-on-dataset-level-and-image-level-omero-tables/50180/) en raison de comportements “étranges” de OMERO.parade par moments.
### Qu’utiliser: tableau ou CSV?
L’utilisation d’OMERO.tables et du script “Populate Metadata” a été décrite précédemment, et a quelques avantages. Toutefois, il n’est pas recommandé d’utiliser OMERO.tables en plus de OMERO.parade. D’après les retours d’expérience (https://wiki-biop.epfl.ch/en/Image_Storage/OMERO/OmeroParade), celle-ci est peu pratique (impossible d’utiliser plusieurs tables) et buggée.
Pour cette raison, il sera préférable d’en rester aux fichiers CSV.
Créer un fichier CSV compatible avec OMERO.parade
Dans la logique de fonctionnement de OMERO.parade, un fichier CSV est associé à un dataset OMERO, où une ligne correspond à une image. Dans cette configuration:
- La première ligne correspond aux headers
- Une colonne (généralement la première colonne) correspond aux identifiants des images (avec le header “Image”)
- Une colonne (généralement la deuxième colonne) correspond aux nom de fichier des images (avec le header “Image_Name”)
- Les autres colonnes correspondent aux autres données (dans les headers, séparer chaque mot par “_”, pas d’espace)
Attacher le fichier en tant que pièce jointe au dataset.
Avant de pouvoir afficher le nom du fichier CSV dans les listes déroulantes “Add filter” et “Add table data…”, vous devrez (étrangement) sortir le dataset du projet et le placer directement en racine de l’utilisateur OMERO.
Filtrer les données grâce à OMERO.parade
Sur la fenêtre principale d’OMERO.web, à la place de “Thumbnails”, sélectionner “Parade”.
OMERO.MAPR
https://github.com/ome/omero-mapr
Cette application permet la recherche de données par attributs (paires clés/valeurs) liés aux images.
Elle permet d’afficher les champs de recherche par clé sur la barre d’outils OMERO, comme on peut le voir sur le frontend OMERO.web de IDR Microscopy (https://idr.openmicroscopy.org/webclient/userdata/)